|
Global outage due to Friday’s release of CrowdStrike
|
Posts: 16,565
Threads: 10,419
Thanks Received: 9,394 in 7,540 posts
Thanks Given: 10,385
Joined: 12 September 18
 19 July 24, 15:46
19 July 24, 15:46
Quote:The story of how CrowdStrike released an update on a Friday and brought down thousands, tens of thousands, or maybe even hundreds of thousands of computers around the world.
Ever heard the unspoken rule: “Never release on Friday”? We have, but CrowdStrike hasn’t. They released a tiny driver on an ordinary Friday morning, which became the cause of a huge outage all over the world.
An incorrect update for CrowdStrike’s EDR (Endpoint Detection and Response) solution has affected Windows devices around the world — giving corporate users the Blue Screen of Death (BSOD). The failure has affected, for example, airport information systems in the US, Spain, Germany, the Netherlands and other countries.
Who else was affected by CrowdStrike’s Friday release and how to roll back bricked computers — all in this post…
What happened
It all started early Friday morning with corporate users around the world reporting problems with Windows. At first, a glitch in Microsoft Azure was blamed, but later CrowdStrike confirmed that the root cause was in the csagent.sys or C-00000291*.sys driver for its CrowdStrike EDR. And it was this driver that caused an abundance of silly office photos showing off the (dreaded) blue screens.
![[Image: crowdstrike-global-cyber-outages-01.jpeg]](https://media.kasperskydaily.com/wp-content/uploads/sites/92/2024/07/19101746/crowdstrike-global-cyber-outages-01.jpeg)
Blue screen of death on all computers = a day off for airport linemen
If we wanted to list everyone affected by this outage, such a list sure wouldn’t fit into this post – or dozens of them. So instead we’ll briefly cover the main victims of CrowdStrike’s negligence. Airline companies, airports, and people who want to either go home or go off on a long-awaited vacation were the most affected:- London’s Heathrow Airport, like many others, announced flight delays due to a technology glitch;
- Scandinavian Airlines posted a notice on its website saying, “Some customers may experience difficulties with their bookings due to an IT issue affecting several countries. SAS is fully operational but delays are expected”;
- In New Zealand, banking, communications and transportation systems are experiencing problems.
Various medical centers, chain stores, the New York subway, the largest bank in South Africa and many other organizations that make lives more comfortable and convenient on a daily basis were affected. The fullest list of those affected by the outage we can find is here — and it’s growing by the minute.
How to fix it
At this stage, it’s rather problematic estimating how long it’ll take to fully restore the affected computers around the world. Things are complicated by the fact that users need to manually reboot their computers in Safe Mode. And in large corporations, this is usually impossible to do on your own without the help of a system administrator.
Nevertheless, here are the instructions for how to get rid of the blue screen of death caused by the CrowdStrike driver update:
- Boot your computer in Safe Mode;
- Go to C:\Windows\System32\drivers\CrowdStrike;
- Locate and delete the csagent.sys or C-00000291*.sys file;
- Restart your computer in normal mode.
And while your sysadmins are doing this, you could use a hack that’s come out of India today: employees of one of the country’s airports have started filling out boarding passes… manually.
![[Image: crowdstrike-global-cyber-outages-02.jpeg]](https://media.kasperskydaily.com/wp-content/uploads/sites/92/2024/07/19102138/crowdstrike-global-cyber-outages-02.jpeg)
India isn’t too worried about the global disruption. Source
How the failure could have been avoidedAvoiding this situation should have been straightforward. First, the update shouldn’t have been released on a Friday. This is as per a rule that’s been known to all in the industry since the year dot: if an error occurs, there’s too little time to fix it before the weekend, so the system administrators at all companies affected need to work over the weekend to fix things.
It’s important to be as responsible as possible about the quality of updates released. We at Kaspersky launched a program back in 2009 to prevent mass failures such as this one at our customers, and passed an SOC 2 audit, which confirms the security of our internal processes. For 15 years now, every update has been subjected to multi-level performance testing on various configurations and operating system versions. This allows us to identify potential problems in advance and resolve them on the spot.
The principle of granular releases should be followed. Updates should be distributed gradually, not all at once to all customers. This approach allows us to react instantly and stop an update if necessary. If our users have a problem, we register it, and its solution becomes a priority at all levels of the company.
As with cybersecurity incidents, in addition to fixing the visible damage, you need to find the root cause to prevent these types of problems repeating in the future. It’s necessary to check software updates on test infrastructure for operability and errors before rolling them out to the company’s “combat” infrastructure, and to implement changes gradually — continually monitoring for possible failures.
Incident handling should be based on an integrated approach to building protection from a trusted supplier with the strictest internal requirements for the security, quality and availability of its services. The basis for this work can be the Kaspersky Next line of solutions. This will help your company not only stay afloat — but also increase the efficiency of your information security system. This can be done either gradually — increasing protection step by step — or all in one go. Protect your infrastructure today with us so that the next global outage doesn’t affect your customers.
And we, for our part, can help you make this decision: switch to Kaspersky and unlock two years of Kaspersky Next EDR Optimum for the price of one. Experience the pinnacle of robust, reliable cybersecurity protection!
...
Continue Reading
Posts: 2,156
Threads: 534
Thanks Received: 7,193 in 2,128 posts
Thanks Given: 1,890
Joined: 14 August 18
The world is still reeling from the massive tech failure that has caused travel chaos around the world, from banking to healthcare services, the world was hit badly.
Flights have been grounded because of the IT outage - a flaw which left many computers displaying blue error screens.
Everywhere around the globe, images are pouring showing long queues, delays and flight cancellations at airports around the world, as passengers had to be manually checked in. Some, because of the turmoil and frustrations just slept on the floor!
Cyber-security firm CrowdStrike has admitted that the problem was caused by an update to its antivirus software, which is designed to protect Microsoft Windows devices from malicious attacks.
Microsoft has said, it is taking "mitigation action" to deal with "the lingering impact" of the outage. The costs from the global outage could easily top $1 billion – BUT the question is WHO PAYS and HOW will they pay (IF they will pay that is...). That is the harder thing to understand there.
CrowdStrike CEO George Kurtz said in an interview Friday morning on CNBC that the firm has been focused on fixing the continuing problems and that so far, he believed most customers had been understanding.
“My goal right now is to make sure every customer is back up and running,” he said. “I think many of the customers understand it’s a complex environment and staying one step ahead of the bad guys requires these content updates.”
"Businesses affected by the outage are likely to find out that traditional business interruption insurance won’t cover them for any of their losses,' said Mark Friedlander, spokesman for the Insurance Information Institute.
"Those policies typically require there to be some kind of physical damage to a business’ property in order for claims to be paid. There is a separate kind of policy for computer outages, known as Business Network Interruption policies, under which claims might be paid. But those polices sometimes only cover malicious hacks and exclude non-malicious computer problems like this one, he said."
Will customers stay?
It’s also not clear how many customers CrowdStrike might lose because of Friday. Wedbush Securities’ Ives estimates less than 5% of its customers might go elsewhere.
“They’re such an entrenched player, to move away from CrowdStrike would be a gamble,” he said. It will be difficult, and not without additional costs, for many customers to switch from CrowdStrike to a competitor. But the real hit to CrowdStrike could be reputational damage that will make it difficult to win new customers.
About CrowdStrike
CrowdStrike has redefined security with the world’s most advanced cloud-native platform that protects and enables the people, processes and technologies that drive modern enterprise. CrowdStrike secures the most critical areas of risk – endpoints and cloud workloads, identity, and data – to keep customers ahead of today’s adversaries and stop breaches. Powered by the CrowdStrike Security Cloud, the CrowdStrike Falcon® platform leverages real-time indicators of attack, threat intelligence on evolving adversary tradecraft and enriched telemetry from across the enterprise to deliver hyper-accurate detections, automated protection and remediation, elite threat hunting and prioritized observability of vulnerabilities – all through a single, lightweight agent. With CrowdStrike, customers benefit from superior protection, better performance, reduced complexity and immediate time-to-value.
The Gartner Magic Quadrant for Endpoint Protection Platforms reveals the relative position of technology providers for a market, helping you make the right choice for your organization. Among 15 other recognized vendors, CrowdStrike was recognized as a Leader positioned highest in Ability to Execute and furthest right in Vision.
For more information, visit the SOURCE sites below.
Images and content from SOURCEs as identified
|
Users browsing this thread: 1 Guest(s)
|
|
Welcome
|
You have to register before you can post on our site.
|
|
Birthdays
|
|
Today's Birthdays
|
 (40)efynu
(40)efynu
|
|
Upcoming Birthdays
|
(39)Tedscolo
|
|
(46)brakasig
|
|
Online Staff
|
| There are no staff members currently online. |

|
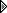 
|



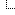 Global outage due to Friday’s release of CrowdStrike
Global outage due to Friday’s release of CrowdStrike
![[-]](https://www.geeks.fyi/images/collapse.png)


![[Image: itmeltdown.png]](https://i.postimg.cc/k4v7fFRN/itmeltdown.png)
![[Image: ap24201683053719.jpg]](https://i.postimg.cc/qqB4Yh2P/ap24201683053719.jpg)