|
Nvidia RTX 30-Series Ampere Architecture Deep Dive: Everything We Know (Updated)
|
Posts: 16,668
Threads: 10,455
Thanks Received: 9,394 in 7,540 posts
Thanks Given: 10,396
Joined: 12 September 18
 16 September 20, 06:33
16 September 20, 06:33
Quote:
Here's how the Ampere architecture changes the underlying elements of the GPU. Get ready for the next round of ray tracing.
The Ampere architecture will power the GeForce RTX 3090, GeForce RTX 3080, GeForce RTX 3070, and other upcoming Nvidia GPUs. It represents the next major upgrade from Team Green and promises a massive leap in performance. Based on current details (the cards come out later this month and in October for the 3070), these GPUs should easily move to the top of our GPU hierarchy, and knock a few of the best graphics cards down a peg or two. Let's get into the details of what we know about the Ampere architecture, including specifications, features, and other performance enhancements.
[Note: We've updated some of the information on the CUDA cores and how it effects performance, provided accurate die size and transistor counts, and additional details on DLSS 2.1 and ray tracing improvements.]
The Ampere architecture marks an important inflection point for Nvidia. It's the company's first 7nm GPU, or 8nm for the consumer parts. Either way, the process shrink allows for significantly more transistors packed into a smaller area than before. It's also the second generation of consumer ray tracing and third generation deep learning hardware. The smaller process provides a great opportunity for Nvidia to radically improve on the previous RTX 20-series hardware and technologies.
We know the Ampere architecture will find its way into upcoming GeForce RTX 3090, RTX 3080, and RTX 3070 graphics cards, and we expect to see RTX 3060 and RTX 3050 next year. It's also part of the Nvidia A100 data center GPUs, which are a completely separate category of hardware. Here we'll break down both the consumer and data center variations of the Ampere architecture and dig into some of the differences.
The launch of Nvidia's Ampere GPUs feels like a blend of 2016's Pascal and 2018's Turing GPus. Nvidia CEO Jensen Huang unveiled the data center focused A100 on May 14, giving us our first official taste of what's to come, but the A100 isn't designed for GeForce cards. It's the replacement for the Volta GV100 (which replaced the GP100). The consumer models have a different feature set, powered by separate GPUs like the GA102, GA104, and so on. The consumer cards also use GDDR6X/GDDR6, where the A100 uses HBM2.
Besides the underlying GPU architecture, Nvidia has revamped the core graphics card design, with a heavy focus on cooling and power. As an Nvidia video notes, "Whenever we talk about GPU performance, it all comes from the more power you can give and can dissipate, the more performance you can get." A reworked cooling solution, fans, and PCB (printed circuit board) are all part of improving the overall performance story of Nvidia's Ampere GPUs. Of course, third party designs are free to deviate from Nvidia's designs.
With the shift from TSMC's 12nm FinFET node to TSMC N7 and Samsung 8N, many expected Ampere to deliver better performance at lower power levels. Instead, Nvidia is taking all the extra transistors and efficiency and simply offering more, at least at the top of the product stack. GA100 for example has 54 billion transistors and an 826mm square die size. That's a massive 156% increase in transistor count from the GV100, while the die size is only 1.3% larger. The consumer GPUs also increase in transistor counts while greatly reducing die sizes.
While 7nm/8nm does allow for better efficiency at the same performance, it also allows for much higher performance at the same power. Nvidia is taking the middle route and offering even more performance at still higher power levels. The V100 was a 300W part for the data center model, and the new Nvidia A100 pushes that to 400W. We see the same on the consumer models. GeForce RTX 2080 Ti was a 250/260W part, and the Titan RTX was a 280W part. The RTX 3090 comes with an all-time high TDP for a single GPU of 350W (that doesn't count the A100, obviously), while the RTX 3080 has a 320W TDP.
What does that mean to the end users? Besides potentially requiring a power supply upgrade, and the use of a 12-pin power connector on Nvidia's own models, it means a metric truckload of performance. It's the largest single generation jump in performance I can recall seeing from Nvidia. Combined with the architectural updates, which we'll get to in a moment, Nvidia says the RTX 3080 has double the performance of the RTX 2080. And if those workloads include ray tracing and/or DLSS, the gulf might be even wider.
Thankfully, depending on how you want to compare pricing, pricing isn't going to be significantly worse than the previous generation GPUs. The GeForce RTX 3090 is set to debut at $1,499, which is a record for a single-GPU GeForce card, effectively replacing the Titan family. The RTX 3080 meanwhile costs $699, and the RTX 3070 will launch at $499, keeping the same pricing as the previous generation RTX 2080 Super and RTX 2070 Super. Does the Ampere architecture justify the pricing? We'll have to wait a bit longer to actually test the hardware ourselves, but the specs at least look extremely promising.
Let's also tackle the efficiency question quickly. At one point in his presentation, Jensen said that Ampere delivers 1.9X the performance per watt as Turing. That sounds impressive, but that appears to be more of a theoretical performance uplift rather than what we'll see on the initial slate of GPUs.
Take the RTX 3080 as an example. It has a 320W TDP, which is nearly 50% more than the 215W TDP of the RTX 2080. Even if it really is double the performance of the RTX 2080, that's still only a 35% improvement in performance per watt.
Nvidia gets the 1.9X figure not from fps/W, but rather by looking at the amount of power required to achieve the same performance level as Turing. If you take a Turing GPU and limit performance to 60 fps in some unspecified game, and do the same with Ampere, Nvidia claims Ampere would use 47% less power.
That's not all that surprising. We've seen power limited GPU designs for a long time in laptops. The RTX 2080 laptops for example can theoretically clock nearly as high as the desktop parts, but they're restricted to a much lower power level, which means actual clocks and performance are lower. A 10% reduction in performance can often deliver a 30% gain in efficiency when you near the limits of a design.
AMD's R9 Nano was another example of how badly efficiency decreases at the limit of power and voltage. The R9 Fury X was a 275W TDP part with 4096 shaders clocked at 1050 MHz. R9 Nano took the same 4096 shaders but clocked them at a maximum of 1000 MHz, and applied a 175W TDP limit. Performance was usually closer to 925MHz in practice, but still at one third less power.
...
Continue Reading
|
Users browsing this thread: 1 Guest(s)
|
|
Welcome
|
You have to register before you can post on our site.
|
|
Birthdays
|
|
Today's Birthdays
|
|
No birthdays today.
|
|
Upcoming Birthdays
|
 (46)
(46)RidgeDimb
|
 (37)ipumaqar
(37)ipumaqar
|
|
(51)tanliorsPeri
|
(43)lapedDow
|
|
(49)rituabew
|
 (37)omyjul
(37)omyjul
|
(41)papedDow
|
|
(50)ArnoldFum
|
|
(38)yfaza
|
 (49)
(49)Kevensi
|
|
(39)boineDon
|
 (50)WillieVot
(50)WillieVot
|
(40)Grompelbawn
|
 (41)
(41)vkseogaF
|
 (37)usogy
(37)usogy
|
|
(40)ywixazok
|
 (38)ixoqe
(38)ixoqe
|
 (36)pa.OpenTran
(36)pa.OpenTran
|
|
Online Staff
|
| There are no staff members currently online. |

|
|



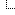 Nvidia RTX 30-Series Ampere Architecture Deep Dive: Everything We Know (Updated)
Nvidia RTX 30-Series Ampere Architecture Deep Dive: Everything We Know (Updated)
![[Image: b9abyGEBbYSzYvzCzNbPZk-970-80.jpg.webp]](https://cdn.mos.cms.futurecdn.net/b9abyGEBbYSzYvzCzNbPZk-970-80.jpg.webp)
![[-]](https://www.geeks.fyi/images/collapse.png)